What If Frontend Frameworks Were Designed for AI? A Token-First Approach to UI Syntax
React components average 340 tokens. What if the same UI could be expressed in 210? I'm designing a syntax where AI generates UI with 38% fewer tokens, zero className strings, and no closing tags.
Last week I published a post where I built the same app in five frameworks. React, Svelte, Vue, SolidJS, Next.js — the usual suspects. I counted lines, measured DX, compared architectural choices. It was the kind of comparison post that makes you feel smart for a day and then changes nothing.
But something nagged me after I hit publish. I kept staring at the numbers. Not the line counts — the token counts.
Because here's the thing nobody in the framework discourse wants to talk about: we're not the primary authors of UI code anymore. AI is. And every framework we use today was designed for a world where a human typed every character.
I've been writing frontend code for 20 years. Shipped at 5 companies. Watched jQuery give way to Backbone give way to Angular give way to React. Every generation solved real problems. But they all share one assumption — that a person is sitting at a keyboard, deciding how to structure every div.
That assumption is dead. And I think we need a syntax designed for what comes next.
The Problem: AI Is Paying a Tax on Every Component
When you ask Claude or GPT-4 to generate a React counter component, here's what it produces:
import React, { useState, useMemo } from 'react';
export default function Counter() {
const [count, setCount] = useState(0);
const isZero = useMemo(() => count === 0, [count]);
return (
<div className="flex items-center justify-center min-h-screen">
<div className="bg-white rounded-xl shadow-lg p-8 max-w-md">
<div className="flex flex-col gap-6">
<h2 className="text-2xl font-bold">Counter</h2>
<span className="text-4xl font-bold">{count}</span>
<div className="flex gap-2">
<button
className="bg-red-500 text-white px-4 py-2 rounded"
onClick={() => setCount(c => c - 1)}
disabled={isZero}
>
- Subtract
</button>
<button
className="bg-blue-500 text-white px-4 py-2 rounded"
onClick={() => setCount(c => c + 1)}
>
+ Add
</button>
</div>
</div>
</div>
</div>
);
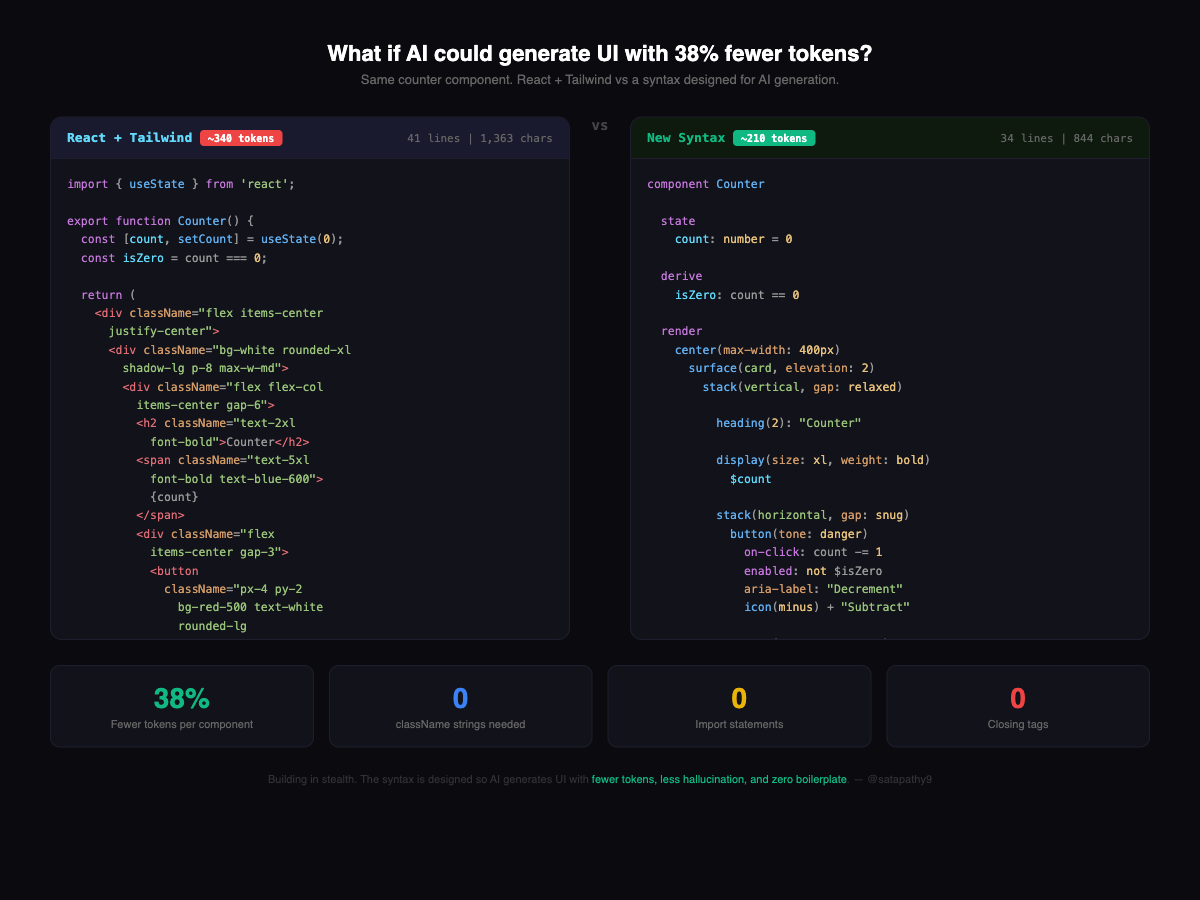
}That's 1,363 characters, 41 lines, roughly 340 tokens.
Now look at every line. Count the ceremony. The import statement that every React component needs. The useState and useMemo hooks with their array destructuring. The className strings — just look at them: "flex items-center justify-center min-h-screen" is 7 tokens of layout that could be expressed as a single semantic word. The closing tags that mirror the opening tags, doubling your structural tokens for zero information gain. The arrow functions wrapping state updates. The curly braces around every expression.
This is fine when a human is writing it. Humans don't pay per character. But when AI generates 80% of your UI — and that's where we're headed if we're not already there — every unnecessary token is a cost.
Not a metaphorical cost. A literal one. API pricing is per-token. And we're burning tokens on </div> and className="flex flex-col gap-6".
The Numbers: What If We Could Do Better?
I've been designing a new syntax. Not hypothetically — I'm actually building this. And here's the same counter component:
component Counter
state
count: number = 0
derive
isZero: count == 0
render
center(max-width: 400px)
surface(card, elevation: 2)
stack(vertical, gap: relaxed)
heading(2): "Counter"
display(size: xl, weight: bold)
$count
stack(horizontal, gap: snug)
button(tone: danger)
on-click: count -= 1
enabled: not $isZero
icon(minus) + "Subtract"
button(tone: primary)
on-click: count += 1
icon(plus) + "Add"That's 844 characters, 34 lines, roughly 210 tokens.
38% fewer tokens. Same UI. Same behavior. Same result in the browser.
And this isn't a cherry-picked case. I've been running comparisons across components of varying complexity:
| Component | React + Tailwind | New Syntax | Token Savings |
|---|---|---|---|
| Counter | ~340 tokens / 1,363 chars / 41 lines | ~210 tokens / 844 chars / 34 lines | 38% |
| Data Dashboard | ~1,250 tokens / 5,000+ chars / 120+ lines | ~740 tokens / 2,956 chars / 84 lines | ~40% |
| Todo List | ~875 tokens / 3,500+ chars | ~570 tokens / 2,268 chars / 63 lines | ~35% |
The savings are consistent. Somewhere between 35-40% across every component I've tested.
Where those ~340 tokens actually go:
| Token Sink | Tokens | % of Total | Eliminated? |
|---|---|---|---|
| Actual UI logic | ~120 | 35% | Kept (this is the real work) |
| className strings | ~85 | 25% | Eliminated (semantic primitives) |
| JSX tags + closing tags | ~55 | 16% | Eliminated (indentation-based) |
| Hook boilerplate | ~30 | 9% | Eliminated (state/derive blocks) |
| Import statements | ~25 | 7% | Eliminated (self-contained) |
| Curly braces + arrows | ~25 | 7% | Eliminated (inline expressions) |
65% of React tokens are structural noise. The new syntax keeps the 35% that matters.
Why the Syntax Works: Eight Sources of Token Savings
The savings don't come from one clever trick. They come from systematically eliminating every source of token waste in modern frontend code.
1. No Import Statements
React:
import React, { useState, useMemo, useCallback } from 'react';New syntax: nothing. Components are self-contained. The compiler knows what you're using from context. That import line is roughly 15 tokens of pure overhead, repeated in every single component file.
2. No className Strings
This is the big one. Look at a typical Tailwind class list:
className="flex items-center justify-center gap-6 bg-white rounded-xl shadow-lg p-8"
That's 15+ tokens of styling information. In the new syntax, the equivalent is:
center(max-width: 400px)
surface(card, elevation: 2)Styling is semantic. surface(card, elevation: 2) tells you it's a card with a shadow. You don't need to memorize that shadow-lg maps to a specific box-shadow value or that rounded-xl means 12px border-radius. The compiler handles the mapping.
This matters for AI especially. When an LLM generates Tailwind classes, it's selecting from thousands of utility permutations. "flex items-center justify-center gap-6 bg-white rounded-xl shadow-lg p-8" — every one of those space-separated tokens is a decision point where the model can hallucinate. bg-white-500 isn't a thing, but the model might generate it. gap-7 exists in some configs but not others. The hallucination surface is enormous.
Semantic primitives collapse that surface to near zero. tone: danger is either valid or it isn't. There's no tone: kinda-danger.
3. No Closing Tags
React:
<div className="flex flex-col gap-6">
<h2>Counter</h2>
<span>{count}</span>
</div>New syntax:
stack(vertical, gap: relaxed)
heading(2): "Counter"
display(size: xl, weight: bold)
$countIndentation defines nesting, like Python. Every </div>, </span>, </button> in JSX is a token that carries zero new information — it just mirrors the opening tag. The parser already knows the structure from indentation. Why make AI generate it twice?
4. No JSX Ceremony
No angle brackets. No curly braces for expressions. No {count} when $count does the same thing in fewer characters. No () => setCount(c => c + 1) when count += 1 says the same thing.
5. State is a Block, Not a Hook
React:
const [count, setCount] = useState(0);New syntax:
state
count: number = 0useState with array destructuring is 10 tokens. A state block with a type annotation is 5. And the state block scales — add 10 state variables and you add 10 lines, not 10 separate useState calls with 10 separate setter functions.
6. Derived Values Are Declarative
React:
const isZero = useMemo(() => count === 0, [count]);New syntax:
derive
isZero: count == 0No dependency arrays. No arrow functions. The compiler figures out what depends on what. This is similar to what Svelte does with $: — but cleaner, and grouped into a dedicated block.
7. Event Handlers Are Inline Expressions
React:
onClick={() => setCount(c => c + 1)}New syntax:
on-click: count += 1
This is the single highest token-savings line in the entire syntax. React's event handler pattern — the onClick, the arrow function, the setter function, the callback pattern — is roughly 12 tokens. The new syntax is 5.
8. Layout Is Semantic
React + Tailwind:
<div className="flex flex-col gap-6">New syntax:
stack(vertical, gap: relaxed)stack, center, surface — these are layout primitives that describe what the layout is, not how to implement it with CSS flexbox utilities. The compiler emits the right CSS. AI doesn't need to remember whether it's flex-col or flex-column or flex-direction: column.
Typed Data Loading: Where It Gets Interesting
The counter example is intentionally simple. Here's where the syntax really shines — a data dashboard with typed API loading:
component DataDashboard
load
metrics: GET /api/metrics -> entity {
totalUsers: number,
activeToday: number,
revenue: currency,
conversionRate: percent
}
recentOrders: GET /api/orders/recent -> list<entity {
id: text,
customer: text,
amount: currency,
status: enum(pending, shipped, delivered, cancelled)
}>Think about what this replaces in React. A useEffect with a fetch call, .then() chains or async/await, a loading state, an error state, a TypeScript interface definition, probably a try/catch block, and maybe a custom hook to wrap all of that. Easily 30-40 lines and 200+ tokens.
In the new syntax, data loading is a first-class block. The types are inline. The compiler generates the loading states, error boundaries, and type safety. The AI just has to declare what data it needs and what shape it comes in.
The currency, percent, and enum() types are semantic — they tell the compiler how to render the data, not just what type it is. revenue: currency means the compiler knows to format it with a currency symbol. status: enum(pending, shipped, delivered, cancelled) means the compiler can generate a type-safe status badge without the AI specifying colors and labels for each variant.
| React + Tailwind | New Syntax | |
|---|---|---|
| Styling | className="flex items-center justify-center gap-6 bg-white rounded-xl..." | center(max-width: 400px) |
| Tokens | 15+ tokens for one element | 5 tokens for same layout |
| AI needs to | Memorize thousands of Tailwind classes | Use semantic primitives it already knows |
| Hallucination risk | High — typos, wrong classes, invalid combos | Low — fewer valid options, less surface area |
The Compiler: Rust, No Virtual DOM
The syntax compiles to optimized browser JavaScript. Similar to how Svelte compiles — no virtual DOM, no runtime diffing. The compiler is written in Rust.
I'm not going to get into implementation details here. That's a separate post (or series of posts). The point for this article is that the syntax is not interpreted — it compiles down to the same kind of JavaScript you'd write by hand if you were optimizing for performance. The semantic primitives like surface(card, elevation: 2) and stack(vertical, gap: relaxed) emit exactly the CSS you'd expect, with no runtime overhead.
The AI-Native Argument
Let me be blunt about why this matters.
We're in a transition period where AI generates most UI code but we're still using syntaxes designed for human authorship. That mismatch has real costs:
Token cost at scale. If you're generating 70 components for a project and each component saves 38% of its tokens, that's a significant reduction in API costs. At the scale companies are starting to operate — generating hundreds or thousands of components — the savings are not trivial.
Hallucination surface. This one is underappreciated. Every unnecessary character an LLM generates is a chance for it to generate the wrong character. A className string like "flex items-center justify-center gap-6 bg-white rounded-xl shadow-lg p-8" has at least 8 independent points where the model could hallucinate an invalid class. Semantic primitives reduce the vocabulary to a small, well-defined set. Less choice means less chance to be wrong.
Context window efficiency. When your entire component fits in 210 tokens instead of 340, you can fit more components in the same context window. That means AI can see more of your codebase at once, which means better consistency across components and smarter decisions about shared state and layout patterns.
Generation speed. Fewer tokens means faster generation. When AI is generating UI in real-time — think AI-assisted editors, copilot-style tools, or AI agents that build entire pages — the speed difference between 340 and 210 tokens per component is noticeable. Multiply by dozens of components and it's significant.
"Just Use Svelte / Pug / HAML"
I know what you're thinking. Svelte already compiles away the runtime. Pug already uses indentation-based nesting. HAML already drops closing tags.
None of them were designed with AI token consumption as a primary constraint. Svelte still uses HTML-like syntax with closing tags. Pug is a template language, not a component model. HAML is a Ruby-era solution to a 2026 problem.
The syntax I'm designing starts from a different question: what is the minimum number of tokens needed to unambiguously describe a UI component? Not "how do we make HTML more pleasant" but "how do we design a syntax that is maximally information-dense for an LLM to generate?"
That means semantic primitives over utility classes. Blocks over hooks. Indentation over closing tags. Inline expressions over callback wrappers. Every design decision is filtered through: does this reduce tokens without losing expressiveness?
What's Next
I'm still building this. The compiler works. The syntax handles real-world components — counters, dashboards, todo lists, data tables, forms. I have about 70 components built in this syntax so far, and the token savings hold steady in the 35-40% range.
There's a lot more to say about the compiler architecture, the semantic styling system, the type system for data loading, and what the developer experience looks like when you're working with AI in this syntax instead of in React.
But this post is already long enough. If you're interested in a syntax designed for the world where AI writes most of the code, follow along. I'll be sharing more as it comes together.
The frameworks we have today are incredible. React changed everything. Svelte proved compilation is the future. Vue proved developer ergonomics matter. I'm not here to replace them — I'm here to ask what comes after them, in a world where the primary author of UI code isn't a person anymore.
Twenty years of writing frontend code, and this is the most excited I've been about a new project in a long time.
I write about what I'm building at sidharthsatapathy.com. This is Day 9 of my daily blog series. If you're building at the intersection of AI and frontend, I'd love to hear what you're working on — find me @satapathy9 on X.

Related Posts
I Built the Same App in 5 Frameworks: Next.js vs React vs Solid vs Svelte vs Vue
Same Cal.com clone. 5 frameworks. Here's what I learned about DX, architecture, and which one I'd pick for production in 2026.
My Claude Code Setup: 7 MCP Servers, Custom Hooks, and an AI That Tweets For Me
How I turned Claude Code into a full operating system -- with 7 MCP servers, security hooks, and custom skills that let AI operate my entire dev stack and social media.
Building Resilient Systems for AI-Powered Applications
Today I learned that the boring parts of software engineering—error handling, progress saving, file deduplication—are what separate toy projects from production systems.